一、基础数据结构
1、数组/链表
前缀和数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class PrefixSum { private int [] prefix;public PrefixSum (int [] nums) { new int [nums.length + 1 ]; for (int i = 1 ; i < prefix.length; i++) { 1 ] + nums[i - 1 ];public int query (int left, int right) { return prefix[right + 1 ] - prefix[left];
[x] 303、区域和检索 - 数组不可变
[x] 304、⼆维区域和检索 - 矩阵不可变
[x] 剑指 Offer II 013. ⼆维⼦矩阵的和
[x] 1314、矩阵区域和
[x] 1352、最后K个数的乘积
[x] 238、除自身以外数组的乘积 双向前缀数组
[x] 523、连续的子数组和 (前缀和+哈希表(取余))
[x] 525、连续数组 (前缀和+哈希表)
[x] 560、和为K的子数组 (前缀和+哈希表)
[x] 325、和等于k的最长子数组长度
[x] 724、寻找数组的中心下标
[ ] 862、和至少为K的最短子数组
[ ] 918、环形子数组的最大和
[ ] 947、和可被 K 整除的⼦数组
[x] 剑指 Offer 66 - 构建乘积数组
差分数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Difference {private int [] diff;public Difference (int [] nums) {assert nums.length > 0 ;new int [nums.length];0 ] = nums[0 ];for (int i = 1 ; i < nums.length; i++) {1 ];public void increment (int i, int j, int val) {if (j + 1 < diff.length) {1 ] -= val;public int [] result() {int [] res = new int [diff.length];0 ] = diff[0 ];for (int i = 1 ; i < diff.length; i++) {1 ] + diff[i];return res;
[x] 370、区间加法
[x] 1109、航班预订统计
[x] 1094、拼车
哈希数组
常数时间内删除/查找数组中的任意元素
核⼼思想 :
1、如果想⾼效地,等概率地随机获取元素,就要使⽤数组作为底层容器。
2、如果要保持数组元素的紧凑性,可以把待删除元素换到最后,然后 pop 掉末尾的元素,这样时间复杂度就是 O(1) 了。当然,我们需要额外的哈希表记录值到索引的映射。
双指针秒杀链表
1、合并两个有序链表
2、单链表分解
3、合并K个有序链表 (优先队列)
4、单链表的倒数第k个节点
双节点,一个节点先走k步,再一起向后走n-k步
5、单链表的中点
快慢指针
6、判断链表是否包含环
快慢指针:一个fast指针每次走两步,一个slow指针每次走一步,如果两个指针最后能相遇,那么链表中一定存在环。如果要检测入环的第一个节点,可以把fast指向head,因为fast和slow相遇时路程正好差一倍,之后两个指针每次走一步,那么再次相遇一定就是第一次入环的节点。
7、两个链表是否相交
链表双指针经典高频题
[x] 2、两数相加
[x] 445、两数相加 II (如果不用翻转列表就用栈来模拟)
[x] 67、⼆进制求和
[ ] 剑指 Offer II 025. 链表中的两数相加
[x] 141、环形链表
[x] 142、环形链表 II
[x] 160、相交链表
[x] 19、删除链表的倒数第 N 个结点
[x] 21、合并两个有序链表
[x] 23、合并 K 个升序链表
[x] 86、分隔链表
[x] 876、链表的中间结点
[ ] 剑指 Offer 25、合并两个排序的链表
[ ] 剑指 Offer 52、两个链表的第⼀个公共节点
[ ] 剑指 Offer II 021. 删除链表的倒数第 n 个结点
[ ] 剑指 Offer II 022. 链表中环的⼊⼝节点
[ ] 剑指 Offer II 023. 两个链表的第⼀个重合节点
[ ] 剑指 Offer II 078. 合并排序链表
[ ] 1305、两棵⼆叉搜索树中的所有元素
[ ] 264、丑数 II
[ ] 313、超级丑数
[ ] 88、合并两个有序数组
[ ] 97、交错字符串
[ ] 977、有序数组的平⽅
[ ] 剑指 Offer 49. 丑数
[ ] 剑指 Offer 18. 删除链表的节点
[ ] 360、有序转化数组
[ ] 355、设计推特
[ ] 373、查找和最⼩的 K 对数字
[ ] 378、有序矩阵中第 K ⼩的元素
[ ] 剑指 Offer II 061. 和最⼩的 k 个数对
[ ] 24、两两交换链表中的节点
[ ] 25、K 个⼀组翻转链表
[ ] 82、删除排序链表中的重复元素 II
[ ] 83、删除排序链表中的重复元素
[ ] 92、反转链表 II
[ ] 1650、⼆叉树的最近公共祖先 III
[ ] 1257、最⼩公共区域
[ ] 234、回⽂链表
[ ] 剑指 Offer II 027. 回⽂链表
[ ] 1201、丑数 III
双指针秒杀数组
双指针技巧主要包括左右指针和快慢指针
快慢指针
数组问题中⽐较常⻅的快慢指针技巧,是让你原地修改数组。
类似扩展(快慢指针):
[x] 83、删除排序链表中的重复元素
[x] 27、移除元素
[x] 283、移动零
左右指针
1、二分查找
1 2 3 4 5 6 7 8 9 10 11 12 13 int binarySearch (int [] nums, int target) {int left = 0 , right = nums.length - 1 ; while (left <= right) {int mid = left + (right - left) / 2 ;if (nums[mid] == target)return mid; else if (nums[mid] < target)1 ; else if (nums[mid] > target)1 ; return -1 ;
2、两数之和
twoSum函数
1 2 3 4 5 6 7 8 9 10 11 12 int [] twoSum(int [] nums, int target) {int left = 0 , right = nums.length - 1 ;while (left < right){int sum = nums[left] + nums[right];if (sum == target){return new int []{left, right};if (sum > target) right--;else left++;return new int []{-1 , -1 };
nSum问题模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public List<List<Integer>> fourSum (int [] nums, int target) {return nSum(nums, 4 , 0 , target);private List<List<Integer>> nSum (int [] nums, int n, int start, int target) {int len = nums.length;new ArrayList <List<Integer>>();if (n < 2 || len < n)return res;if (n == 2 ) {int small = start, big = len - 1 ;while (small < big) {int left = nums[small], right = nums[big];int sum = left + right;if (sum == target) {new ArrayList <Integer>(Arrays.asList(left, right)));while (small < big && nums[small] == left)while (small < big && nums[big] == right)else if (sum > target) {while (small < big && nums[big] == right)else if (sum < target) {while (small < big && nums[small] == left)else {int i = start;while (i < len) {int now = nums[i];1 , i + 1 , target - now);for (List<Integer> s : sub) {while (i < len && nums[i] == now)return res;
3、反转数组
例:反转一个char[]数组
1 2 3 4 5 6 7 8 9 10 void reverseString (char [] s) {int left = 0 , right = s.length - 1 ;while (left < right){char temp = s[left];
4、回文串判断
1 2 3 4 5 6 7 8 9 10 11 boolean isPalindrome (String s) {int left = 0 , right = s.length() - 1 ;while (left < right){if (s.charAt(left) != s.charAt(right)){return false ;return true ;
难度提升:
核⼼ 是从中⼼向两端扩散的双指针技巧
1 2 3 4 5 6 7 8 9 10 palindrome (String s, int l, int r) {while (l >= 0 && r < s.length() && s.charAt(l) == s.charAt(r)){return s.substring(l+1 , r);
数组双指针经典高频题
二分搜索
[x] 34、在排序数组中查找元素的第⼀个和最后⼀个位置
[x] 704、⼆分查找
[x] 剑指 Offer 53 - I. 在排序数组中查找数字 I
[x] 35、搜索插⼊位置
[x] 剑指 Offer II 068. 查找插⼊位置
[x] 240、搜索⼆维矩阵 II (从右上角遍历)
[x] 566、重塑矩阵
[x] 74、搜索⼆维矩阵
[ ] 剑指 Offer 04. ⼆维数组中的查找
[x] 519、随机翻转矩阵
[ ] 354、俄罗斯套娃信封问题
[ ] 392、判断⼦序列
[x] 658、找到 K 个最接近的元素
[ ] 793、阶乘函数后 K 个零
[ ] 852、⼭脉数组的峰顶索引
[ ] 剑指 Offer II 069. ⼭峰数组的顶部
[ ] 1011、在 D 天内送达包裹的能⼒
[ ] 875、爱吃⾹蕉的珂珂
[ ] 剑指 Offer II 073. 狒狒吃⾹蕉
[ ] 1201、丑数 III
[ ] 剑指 Offer 53 - II. 0~n-1中缺失的数字
滑动窗口
维护⼀个窗⼝,不断滑动,然后更新答案
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 Void slidingWindow (String s) {new HashMap <>();int left = 0 , right = 0 ;while (right < s.length()){char c = s[right];while (window needs shrink){char d = s[left];
[x] 76、最小覆盖子串
[x] 567、字符串的排列
[x] 438、找到字符串中所有字母异位词
[x] 3、无重复字符的最长子串
二分查找详细
基本的二分搜索:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int binarySearch (int [] nums, int target) {int left = 0 ; int right = nums.length - 1 ; while (left <= right) {int mid = left + (right - left) / 2 ;if (nums[mid] == target)return mid; else if (nums[mid] < target)1 ; else if (nums[mid] > target)1 ; return -1 ;
寻找左侧边界的二分搜索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int left_bound (int [] nums, int target) {int left = 0 ;int right = nums.length; while (left < right) { int mid = left + (right - left) / 2 ;if (nums[mid] == target) {else if (nums[mid] < target) {1 ;else if (nums[mid] > target) {return left;
将其改写为搜索两端都封闭的写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int left_bound (int [] nums, int target) {int left = 0 , right = nums.length - 1 ;while (left <= right) {int mid = left + (right - left) / 2 ;if (nums[mid] < target) {1 ;else if (nums[mid] > target) {1 ;else if (nums[mid] == target) {1 ;if (left == nums.length) return -1 ;return nums[left] == target ? left : -1 ;
寻找右侧边界的二分搜索:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int right_bound (int [] nums, int target) {int left = 0 , right = nums.length;while (left < right) {int mid = left + (right - left) / 2 ;if (nums[mid] == target) {1 ; else if (nums[mid] < target) {1 ;else if (nums[mid] > target) {return left - 1 ;
将其改写为搜索两端都封闭的写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int right_bound (int [] nums, int target) {int left = 0 , right = nums.length - 1 ;while (left <= right) {int mid = left + (right - left) / 2 ;if (nums[mid] < target) {1 ;else if (nums[mid] > target) {1 ;else if (nums[mid] == target) {1 ;if (left - 1 < 0 ) return -1 ;return nums[left - 1 ] == target ? (left - 1 ) : -1 ;
链表递归操作
1、递归反转链表
1 2 3 4 5 6 7 8 9 ListNode reverse (ListNode head) {if (head == null || head.next == null ){return head;ListNode last = reverse(head.next);null ;return last;
2、反转链表前N个节点
1 2 3 4 5 6 7 8 9 10 11 ListNode successor = null ;reverseN (ListNode head, int n) {if (n == 1 ){return head;ListNode last = reverseN(head.next, n-1 );return last;
3、反转链表的一部分
给定一个索引区间,仅仅反转区间中的链表元素
1 2 3 4 5 6 7 ListNode reverseBetween (ListNode head, int m, int n) {if (m == 1 ){return reverseN(head, n);1 , n-1 );return head;
2、队列/栈
队列主要⽤在BFS算法,栈主要⽤在括号相关的问题
括号问题
1、判断有效括号串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public boolean isValid (String s) {new Stack <>();for (char c : s.toCharArray()){if (c == '(' || c == '{' || c == '[' ){else {if (!left.isEmpty() && leftOf(c) == left.peek()){else return false ;return left.isEmpty();char leftOf (char c) {if (c == '}' )return '{' ;if (c == ')' )return '(' ;return '[' ;
2、平衡括号串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public int minAddToMakeValid (String s) {int res = 0 ;int need = 0 ;for (char c : s.toCharArray()){if (c == '(' ){else {if (need == -1 ){0 ;return res + need;
进阶:现在假设1个左括号需要匹配2个右括号才叫做有效的括号组合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public int minInsertions (String s) {int res = 0 , need = 0 ;for (int i = 0 ; i < s.length(); i++) {if (s.charAt(i) == '(' ) {2 ;if (need % 2 == 1 ) {if (s.charAt(i) == ')' ) {if (need == -1 ) {1 ;return res + need;
单调栈
模板
1 2 3 4 5 6 7 8 9 10 11 12 13 int [] nextGreaterElement(int [] nums){int n = nums.length;int [] res = new int [n]; new Stack <>();for (int i = n - 1 ; i >= 0 ; i--){while (!s.isEmpty() && s.peek() <= nums[i]){1 : s.peek();return res;
[x] 496.下一个更大元素I
[x] 739、每日温度
[x] 316、去除重复字母
环形数组
一般通过 % 运算符求模(余数),来模拟环形特效
1 2 3 4 5 6 int [] arr = {1 , 2 , 3 , 4 , 5 };int n = arr.length, index = 0 ;while (true ) {
通常还是调用单调栈模板,常用套路是将数组长度翻倍(可以不⽤构造新数组,⽽是利⽤循环数组的技巧来模拟数组⻓度翻倍的效果 )
1 2 3 4 5 6 7 8 9 10 11 12 13 public int [] nextGreaterElements(int [] nums) {int n = nums.length;int [] res = new int [n];new Stack <>();for (int i = 2 * n - 1 ; i >= 0 ; i--) {while (!s.isEmpty() && s.peek() <= nums[i % n]) {1 : s.peek();return res;
单调队列
单调队列相比较优先级队列,除了能够维护最值,还能够维护队列元素的相对顺序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class MonotonicQueue {new LinkedList <>();public void push (int n) {while (!maxq.isEmpty() && maxq.getLast() < n){public int max () {return maxq.getFirst();public void pop (int n) {if (n == maxq.getFirst()){int [] maxSlidingWindow(int [] nums, int k) { MonotonicQueue window = new MonotonicQueue ();new ArrayList <>();for (int i = 0 ; i < nums.length; i++) { if (i < k - 1 ) { else { 1 ]); } int [] arr = new int [res.size()]; for (int i = 0 ; i < res.size(); i++) { return arr;
LRU算法
LRU 算法设计
1、cache 中的元素必须有时序,以区分最近使⽤的和久未使⽤的数据,当容量满了之后要删除最久未使⽤的那个元素腾位置。
2、我们要在 cache 中快速找某个 key 是否已存在并得到对应的 val;
LRU 缓存算法的核⼼数据结构就是哈希链表,双向链表和哈希表的结合体。
「为什么必须要⽤双向链表」:
删除⼀个节点不光要 得到该节点本身的指针,也需要操作其前驱节点的指针,⽽双向链表才能⽀持直接查找前驱,保证操作的时间复杂度 O(1)
注意我们实现的双链表 API 只能从尾部插⼊,也就是说靠尾部的数据是最近使⽤的,靠头部的数据是最久未使⽤的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class LRUCache {int cap;new LinkedHashMap <>();public LRUCache (int capacity) {this .cap = capacity;public int get (int key) {if (!Cache.containKey(key)){return -1 ;return cache.get(key);public void put (int key, int val) {if (cache.containsKey(key)){return ;if (cache.size() >= this .cap){int oldestKey = cache.keySet().iterator().next();private void makeRecently (int key) {int val = cache.get(key);
二、进阶数据结构
1、二叉树思维
二叉树遍历框架
1 2 3 4 5 6 7 8 9 10 void traverse (TreeNode root) {if (root == null ) {return ;
⼆叉树题⽬的递归解法可以分两类思路,第⼀类是遍历⼀遍⼆叉树得出答案,第⼆类是通过分解问题计算出答案,这两类思路分别对应着 回溯算法核⼼框架 和 动态规划核⼼框架
一、翻转二叉树
1 2 3 4 5 6 7 8 9 10 11 12 public TreeNode invertTree (TreeNode root) {return root;void traverse (TreeNode root) {if (root == null )return ;TreeNode temp = root.left;
二、填充节点的右侧指针
题⽬的意思就是把⼆叉树的每⼀层节点都⽤ next 指针连接起来:
1 2 3 4 5 6 7 8 9 10 11 12 public Node connect (Node root) {if (root == null )return null ;return root;void traverse (Node node1, Node node2) {if (node1 == null && node2 == null )return ;
三、将二叉树展开为链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public void flatten (TreeNode root) {if (root == null )return ;TreeNode left = root.left;TreeNode right = root.right;null ;TreeNode p = root;while (p.right != null ){
2、二叉树构造
通过前序和中序遍历结果构造二叉树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 HashMap<Integer, Integer> map = new HashMap <>();public TreeNode buildTree (int [] preorder, int [] inorder) {for (int i = 0 ; i < inorder.length; i++) {return build(preorder, 0 , preorder.length - 1 , inorder, 0 , inorder.length - 1 );build (int [] preorder, int prestart, int preend, int [] inorder, int instart, int inend) {if (prestart > preend)return null ;int value = preorder[prestart];int index = map.get(value);TreeNode root = new TreeNode (value);int leftSize = index - instart;1 , prestart + leftSize, inorder, instart, index - 1 );1 , preend, inorder, index + 1 , inend);return root;
3、序列化
4、后序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {new HashMap <>();new LinkedList <TreeNode>();public List<TreeNode> findDuplicateSubtrees (TreeNode root) {return list;traverse (TreeNode root) {if (root==null )return "#" ;String left = traverse(root.left);String right = traverse(root.right);String subTree = left + ',' + right + ',' + root.val;int freq = map.getOrDefault(subTree, 0 );if (freq == 1 ){1 );return subTree;
5、归并排序
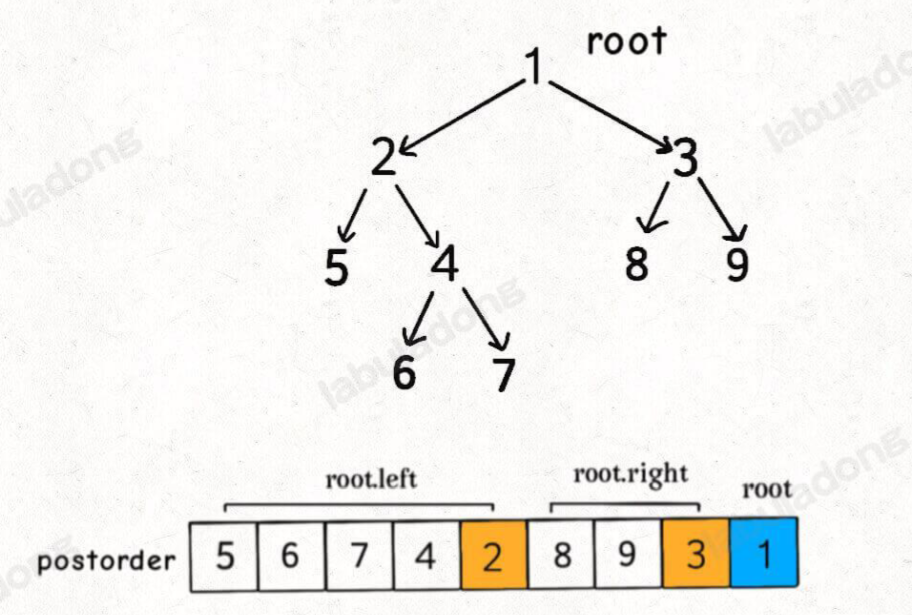
归并排序的过程可以在逻辑上抽象成⼀棵⼆叉树,树上的每个节点的值可以认为是nums[lo…hi] ,叶⼦节点的值就是数组中的单个元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 class Merge {private static int [] temp;public static void sort (int [] nums) {new int [nums.length];0 , nums.length - 1 );private static void sort (int [] nums, int lo, int hi) {if (lo == hi) {return ;int mid = lo + (hi - lo) / 2 ;1 , hi);private static void merge (int [] nums, int lo, int mid, int hi) {for (int i = lo; i <= hi; i++) {int i = lo, j = mid + 1 ;for (int p = lo; p <= hi; p++) {if (i == mid + 1 ) {else if (j == hi + 1 ) {else if (temp[i] > temp[j]) {else {
[x] 315、计算右侧小于当前元素的个数
[x] 493、翻转对
6、二叉搜索树
BST特性 :
1、对于 BST 的每⼀个节点 node,左⼦树节点的值都比 node 的值要小,右⼦树节点的值都比 node 的值大。
BST 的中序遍历结果是有序的(升序)
[x] 230、二叉搜索树中第K小的元素
[x] 538、把二叉搜索树转换为累加树
基操
一、判断BST的合法性
二、在BST中插入一个数
1 2 3 4 5 6 7 8 9 10 11 TreeNode insertIntoBST (TreeNode root, int val) { if (root == null ) return new TreeNode (val); if (root.val < val) if (root.val > val) return root;
三、在BST中删除一个数
1 2 3 4 5 6 7 8 9 10 11 12 TreeNode deleteNode (TreeNode root, int key) { if (root.val == key) { else if (root.val > key) { else if (root.val < key) { return root;
找到⽬标节点了,⽐⽅说是节点 A,如何删除这个节点,这是难点。因为删除节点的同时不能破坏 BST 的性质。有三种情况
情况 1 :A 恰好是末端节点,两个⼦节点都为空,那么它可以删除
情况 2 :A 只有⼀个⾮空⼦节点,那么它要让这个孩⼦接替⾃⼰的位置。
情况 3 :A 有两个⼦节点,麻烦了,为了不破坏 BST 的性质,A 必须找到左⼦树中最⼤的那个节点,或者右 ⼦树中最⼩的那个节点来接替⾃⼰。我们以第⼆种⽅式讲解
1 2 3 4 5 6 7 if (root.left != null && root.right != null ) { TreeNode minNode = getMin(root.right);
三种情况分析完毕,填⼊框架,简化⼀下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 TreeNode deleteNode (TreeNode root, int key) { if (root == null ) return null ; if (root.val == key) { if (root.left == null ) return root.right; if (root.right == null ) return root.left; TreeNode minNode = getMin(root.right); else if (root.val > key) {else if (root.val < key) {return root; getMin (TreeNode node) { while (node.left != null ) node = node.left; return node;
构造
后序
7、快速排序
快速排序是先将一个元素排好序,然后再将剩下的元素排好序 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 class Quick {public static void sort (int [] nums) {0 , nums.length - 1 );private static void sort (int [] nums, int lo, int hi) {if (lo >= hi) {return ;int p = partition(nums, lo, hi);1 );1 , hi);private static int partition (int [] nums, int lo, int hi) {int pivot = nums[lo];int i = lo + 1 , j = hi;while (i <= j) {while (i < hi && nums[i] <= pivot) {while (j > lo && nums[j] > pivot) {if (i >= j) {break ;return j;private static void shuffle (int [] nums) {Random rand = new Random ();int n = nums.length;for (int i = 0 ; i < n; i++) {int r = i + rand.nextInt(n - i);private static void swap (int [] nums, int i, int j) {int temp = nums[i];
变体:快速选择
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 int findKthLargest (int [] nums, int k) {int lo = 0 , hi = nums.length - 1 ;while (lo <= hi) {int p = partition(nums, lo, hi);if (p < k) {1 ;else if (p > k) {1 ;else {return nums[p];return -1 ;int partition (int [] nums, int lo, int hi) {void shuffle (int [] nums) {void swap (int [] nums, int i, int j) {
8、图
图本质上就是个⾼级点的多叉树,适⽤于树的 DFS/BFS 遍历算法,全部适用于图。
常用邻接表和邻接矩阵来实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void traverse (Graph graph, int s) { if (visited[s]) return ; true ; true ; for (int neighbor : graph.neighbors(s)) {
9、拓扑排序
两个图论算法:有向图的环检测、拓扑排序算法
环检测算法(DFS 版本)
⾸先就是把问题转化成「有向图」这种数据结构,只要图中存在环,那就说明存在循 环依赖
如果发现有向图中存在环,那就说明课程之间存在循环依赖,肯定没办法全部上完;反之,如果没有 环,那么肯定能上完全部课程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 class Solution {boolean [] onPath;boolean [] visited;boolean hasCycle = false ;public boolean canFinish (int numCourses, int [][] prerequisites) {new boolean [numCourses];new boolean [numCourses];for (int i = 0 ; i < numCourses; i++) {return !hasCycle;void traverse (List<Integer>[] graph, int s) {if (onPath[s]) {true ;if (visited[s] || hasCycle) {return ;true ;true ;for (int t : graph[s]) {false ;int numCourses, int [][] prerequisites) {new LinkedList [numCourses];for (int i = 0 ; i < numCourses; i++) {new LinkedList <>();for (int [] edge : prerequisites) {int from = edge[1 ];int to = edge[0 ];return graph;
PS:类⽐贪吃蛇游戏,visited 记录蛇经过过的格⼦,⽽ onPath 仅仅记录蛇身。onPath ⽤于判断 是否成环,类⽐当贪吃蛇⾃⼰咬到⾃⼰(成环)的场景。
拓扑排序
如果把课程抽象成节点,课程之间的依赖关系抽象成有向边,那么这幅图的拓扑排序结果就是上课顺序
先判断⼀下题⽬输⼊的课程依赖是否成环,成环的话是⽆法进⾏拓扑排序的。将后序遍历的结果进⾏反转,就是拓扑排序的结果。
210题代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Solution {boolean flag = false ;boolean [] visit;boolean [] onPath;new LinkedList <>();public int [] findOrder(int numCourses, int [][] prerequisites) {new LinkedList [numCourses];new boolean [numCourses];new boolean [numCourses];for (int i = 0 ; i < numCourses; i++){new LinkedList <Integer>();for (int [] j : prerequisites){1 ]].add(j[0 ]);for (int i = 0 ; i < numCourses; i++){if (flag)return new int []{};int [] res = new int [numCourses];for (int i = 0 ; i < preorder.size(); i++){return res;public void traverse (List<Integer>[] path, int s) {if (onPath[s]){true ;if (flag || visit[s])return ;true ;true ;for (int j : path[s]){false ;
环检测算法(BFS 版本)
思路:
1、构建邻接表,和之前⼀样,边的⽅向表示「被依赖」关系。
2、构建⼀个 indegree 数组记录每个节点的⼊度,即 indegree[i] 记录节点 i 的⼊度。
3、对 BFS 队列进⾏初始化,将⼊度为 0 的节点⾸先装⼊队列。
4、开始执⾏ BFS 循环,不断弹出队列中的节点,减少相邻节点的⼊度,并将⼊度变为 0 的节点加⼊队列。
5、如果最终所有节点都被遍历过(count 等于节点数),则说明不存在环,反之则说明存在环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public boolean canFinish (int numCourses, int [][] prerequisites) { int [] indegree = new int [numCourses]; for (int [] edge : prerequisites) { int from = edge[1 ], to = edge[0 ]; new LinkedList <>(); for (int i = 0 ; i < numCourses; i++) { if (indegree[i] == 0 ) { int count = 0 ; while (!q.isEmpty()) { int cur = q.poll(); count++; for (int next : graph[cur]) { if (indegree[next] == 0 ) { return count == numCourses;